

根据摩根士丹利最新发布的一项调查显示,目前只有4%的人表示对于ChatGPT使用有依赖,在交互过程中,用户常常被它们一本正经的胡言乱语所打败——对于部分问题,它们会输出一些“看似非常有道理,实则完全不对”的内容,让人啼笑皆非。之所以出现这种“AI幻觉”,是因为大模型的内容由推理而来,而在其自身训练过程中也不可避免存在数据偏差。因此,当提问超出其训练范围,大模型可能会模糊回答,或者一本正经地胡诌。但是对于数据准确性有着较高要求的用户,这样的通用性大模型可能会是负担,进而导致大模型应用的普及度没有想象的高。
有没有办法改善大模型回答不准确的情况?当然有。既然回答不准确是因为缺少真正有用的知识参考,可以面向特定领域定制行业大模型,将可信来源的数据转化成向量数据存储起来,校准大模型推理输出的结果,从而使大模型输出的结果更加准确。
不过,如果只是依靠向量数据库进行私有化部署,容量有限且速度比较慢,无法完全满足企业通过大模型提质增效的潜在需求。现在,cVector向量计算一体机通过发挥高性能硬件、向量加速算法和并行计算算法的合力,致力于满足亿级乃至百亿千亿向量规模的大模型推理应用向量计算需求。
云创数据cVector 向量计算一体机通过自研的分布式并行计算架构和向量计算硬件加速算法软件,融合高密度向量计算混合服务硬件,实现对大规模向量数据的高效存储、索引与比对,是软硬件一体化的产品。cVector 向量计算一体机在实现功能上类似向量数据库,根据公司内部进行的对比测试,cVector 向量计算一体机在计算方式、入库速度、规模支撑、查询结果等方面较向量数据库更具优势。
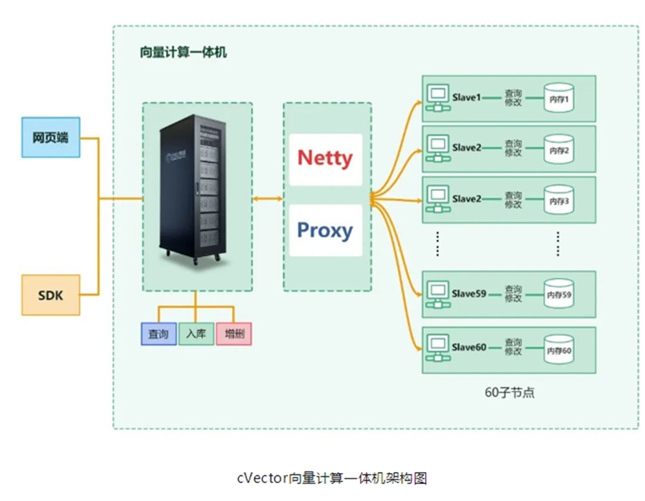
近期, cVector向量计算一体机接受了工信部直属的国家一级科研事业单位中国软件评测中心的鉴定测试。中国软件评测中心对比测试了cVector向量计算一体机与3款主流向量数据库在入库速度、查询速度、准确性等维度的性能对比。
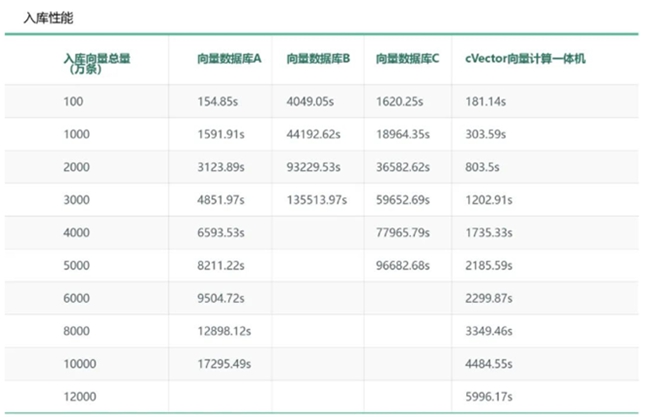
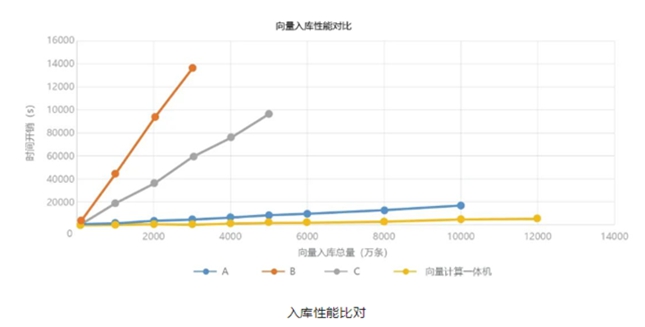
在入库性能方面,同样入库3000万条256 维向量数据,在向量数据库中最快的是A,入库速度是4851.97s,cVector向量计算一体机是1202.91s,入库速度约是向量数据库A的4倍,向量数据库C的50倍,向量数据库B的113倍。
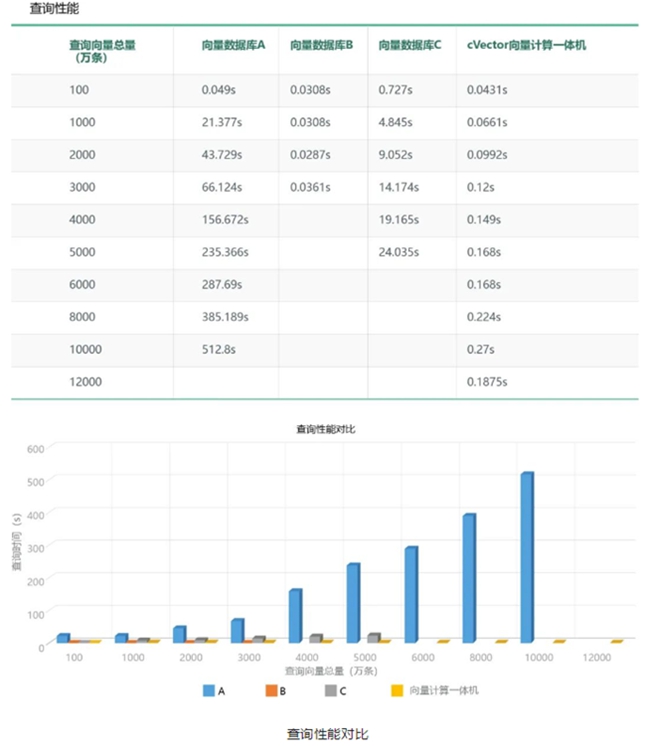
在查询性能方面,同样查询1亿条256 维向量数据,向量数据库A的查询速度是512.8s,cVector向量计算一体机是0.27s,查询速度是前者的1899倍,而其他两家测试向量数据库由于数据量太大无法入库比较。
在准确性方面,cVector 向量计算一体机、向量数据库A、向量数据库B和向量数据库C的数据准确度一致,通过了中国软件评测中心(工业和信息化部软件与集成电路促进中心)单项性能测试。
cVector向量计算一体机在亿级乃至百亿千亿向量规模的的入库和查询等方面具有显著的性能优势,可帮助提高大模型推理的服务性能和服务质量,并能明显降低其基础设施建设成本,助力类ChatGPT等人工智能企业以更优的性价比解决算力不足的问题。
根据中国软件评测中心测试报告结果,“cVector向量计算一体机”在千万级以上规模的入库和查询等方面具有更高的性能优势,可帮助提高大模型推理的服务性能和服务质量。
cVector向量计算一体机主要面向大模型推理应用,能够在下述大模型推理环节发挥显著作用:
①提高生成式AI的输出准确性。
由于大模型的输出结果是根据概率推理而成,所以会出现“一本正经说胡话”的情形。可以将可信来源的数据转化成向量数据存储在向量计算一体机中,校准大模型推理输出的结果,从而使大模型输出的结果更加准确。
②提升大模型理解互联网实时数据的能力。
大模型基于历史数据训练而成,所以“只知道过去,不知道现在”。如果使用向量计算一体机存储海量实时数据所转化成的向量数据,可以帮助大模型理解掌握实时情况。
③提升大模型对用户的服务质量。
向量计算一体机可以允许用户上传更多的数据,让大模型掌握用户个性化的背景资料,更好地学习理解用户请求,更好地结合用户的实际情况回答问题。
④减轻大模型的访问压力。
用户所提的大部分问题都是相似的常见问题,向量计算一体机可以缓存大量热点问题,不需要经过大模型推理即可返回结果,从而大幅减少算力成本。
⑤帮助生成式AI过滤敏感内容。
怎么防止生成式AI说错话一直是一个挑战性问题,而向量计算一体机可以存放敏感内容所对应的向量数据,在用户提出请求时加以判断,尽可能防止AI对敏感问题做出不恰当的回应。
目前在人工智能领域中大规模图像识别比对的应用场景,有力支撑大规模图像的向量比对需求的“cVector向量计算一体机”,在大模型时代的刚需下,前景广阔。期待,云创数据通过技术创新和研发创新,推动我国AI技术领域话语权,以更多元化的产品服务众多领域客户,为社会带来持续不断的发展新动能。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






