

6月13日,云创数据(股票代码:835305)公布了关于北交所2022年年报二次问询函回复,其中关于云创数据“cVector向量计算一体机”的商业价值,让众多投资者高度认可。
AI时代一切AI化,而AI化的本质则是向量化,然而向量化计算成本高昂,由此导致服务质量受限。因此,目前ChatGPT、AutoGPT等主流的生成式AI普遍采用了向量数据库技术以缓解对GPU集群的访问压力、提升对用户的服务质量。
如果说向量数据库给AI插上腾飞的翅膀,那么云创数据的“cVector向量计算一体机”更是为AI划出蓝天。
公司向量计算一体机用算法+CPU代替GPU实现基于硬件加速的向量计算,可以大幅度拓展大模型的时间边界和空间边界,满足亿级以上向量规模的大模型推理应用中所需的向量计算性能需求,特别是在千万级以上规模的入库和查询等方面具有更高的性能优势,可帮助提高大模型推理的服务性能和服务质量,因此具有很高商用价值,成为众多领域解决方案首选。
解决高维向量计算中的算力不足的卡脖子难题,大幅降低算力成本
2022年6月,云创数据正式发布了“cVector向量计算一体机”,针对特征向量计算场景,用优化后的CPU代替GPU,解决高维向量计算中的算力不足的卡脖子难题,大幅降低算力成本。
资料显示,相比传统机架服务器,“cVector向量计算一体机”机能够在同一机柜部署多达300个处理节点,并通过分布式处理资源管理系统形成一个统一处理资源集群,实现单个机柜处理35亿特征值秒级比对能力,单台设备相当于60台普通服务器的处理能力,可广泛应用于当前大模型的算力支撑,具有很高的性价比优势。具体来看:
在人工智能大规模图像检索场景中,“cVector向量计算一体机”较之GPU服务器,同等算力所需成本大幅下降,有助于解决当前同等投入规模情况下,仅依靠GPU算力不足以支撑大规模图像检索应用的难题。
在生成式AI场景中,主要工作是对大模型的训练和推理,其中大模型训练仍是主要依赖GPU的领域,而“cVector向量计算一体机”能够在大模型推理环节中,帮助大模型减轻访问压力、提升理解实时数据能力、提高输出准确性、提升服务质量、过滤敏感内容等。有助于辅助解决仅依靠GPU不足以支撑大模型推理所需算力的难题。
值得我们关注,“cVector向量计算一体机”的软件系统是云创数据依托自主研发的加速算法和并行计算算法运行的,对于我国智能技术细分领域自主可控意义重大。
据了解,云创数据已于2021年10月25日获得了“cVector向量计算一体机”中的自研软件部分的软件著作权(2021SR1552144,云创cVector向量并行比对系统V1.0);同时,公司于2022年11月7日对该软件算法及一体机设备申请了发明专利(2022113813387,一种分布式并行向量比对计算方法及系统,目前处于已受理状态)。
向量规模的大模型推理应用优势阶梯式增长,商业价值明显
作为国家级软硬件产品和信息系统测试实验室,中国软件评测中心对比测试了“cVector向量计算一体机”与3款主流向量数据在入库速度、查询速度、准确性等维度的性能对比,本次测试系中国软件评测中心依据相关标准和规则设置测试环境,同在CPU平台(非GPU平台)下进行的性能对比测试。
(一)性能测试结果
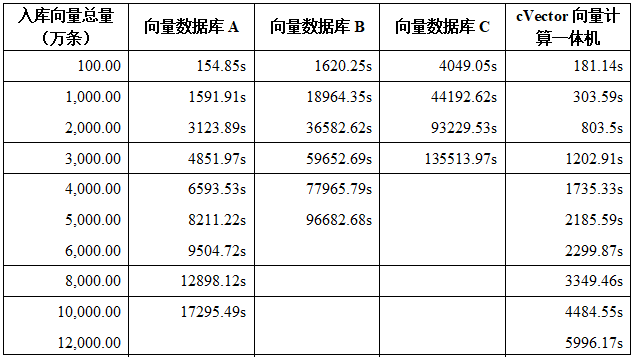
1、数据入库性能
“cVector向量计算一体机V1.0”、向量数据库A、向量数据库B、向量数据库C入库,当向量数据是256维,使用Python3.7.8版本编写代码测试,调用对应库、模块和函数入库,
测试情况如表所示:
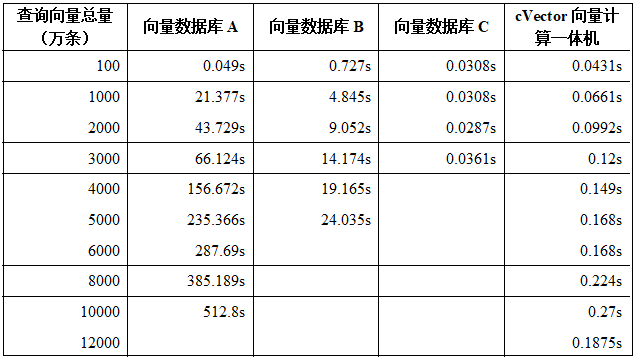
2、数据查询性能
“cVector向量计算一体机V1.0”、向量数据库A、向量数据库B、向量数据库C查询,当向量数据是256维,使用Python3.7.8版本编写代码测试,调用对应库、模块和函数查询,统计返回10条与查询向量距离最接近向量的查询时间,测试情况如表所示:
3、准确度
在“cVector向量计算一体机V1.0”、向量数据库A、向量数据库B和向量数据库C中存储相同的1000万条的256维向量数据,分别查询与目标向量的欧氏距离最短的10条向量,对比结果显示各自返回的10条向量与目标向量的距离值均相同。
根据中国软件评测中心测试报告结果,“cVector向量计算一体机”在千万级以上规模的入库和查询等方面具有更高的性能优势,可帮助提高大模型推理的服务性能和服务质量。
我们有理由相信,能够应用于人工智能领域中大规模图像识别比对的应用场景,有力支撑大规模图像的向量比对需求的“cVector向量计算一体机”,在大模型时代的刚需下,前景广阔。期待,云创数据通过技术创新和研发创新,推动我国AI技术领域话语权,以更多元化的产品服务众多领域客户,为社会带来持续不断的发展新动能。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






